A smooth delivery rhythm is essential for maximizing the benefits of microservices. Get started planning out your pipeline with this guide.
Before you get too far into planning, though, communicate some basic goals. There are some fundamental capabilities that you will enable with microservices and continuous delivery. Every organization has different goals, and they may evolve. Regardless, at least establish the understanding that value will be added to the organization due to the ability to deploy application components to production independently. This should be a part of the organization vision, and you will want to have this conversation early. If you don't take anything else away from this article, at least, heed this warning: stakeholder buy-in to continuous delivery is critical; you will likely need to break some old habits like heavy release planning processes and manual change management. It is best to have folks on your side, or you are going to have a bad time.
Check back for a future post on more organizational impact of microservices and continuous delivery. For now, we can plan the technical goals and derive some user stories (that's Agile speak, I do hope you're not Waterfalling a microservice project).
Source Code
Certain events trigger continuous delivery jobs. Commonly, these are source control events, like a Git commit. This is a great place to start planning, but be careful; topics like Git branching and tagging can be polarizing, because there are many effective options. My advice is to talk about branching and tagging in the context of developer collaboration. Adapt your continuous delivery automation to developer preferences and existing conventions. Avoid the temptation to engineer source control processes that seem conducive to continuous delivery - just about any sane set of conventions that works logistically for collaboration will be fine. However, the one convention that I highly recommend in microservice environments is that each microservice has its own repository.
Identify the events should have impact on the continuous delivery pipeline, and define what should be triggered in general terms. Below is one possible outcome of this planning exercise:
- commit to master branch - trigger production continuous delivery pipeline
- pull request - trigger delivery to ephemeral integration environment for testing
These are just a couple examples. The first, is a very common event trigger, and maybe the only one you need. The second example, is less common, but one of my favorite patterns. If your source control system has the ability to send notifications about pull requests, or you can detect them programmatically, you may want to kick off tests or even spin up a single-use environment for observation.
If you are using an Agile methodology, these high-level use cases are good user story candidates:
As a developer, when I perform a Git commit to the main branch of a microservice repository, the production delivery pipeline is triggered
That is a bite-sized implementation effort with measurable success criteria. You don't have to have the whole pipeline in place to demonstrate a Git commit hook triggering a build job.
Dependencies
You may have an existing microservice architecture or at least a design in mind. Identify dependencies for each microservice like databases, libraries, base images, or other services. Categorize dependencies like this:
- absolutely immutable
- build-time variable
- run-time variable
Immutable Dependencies
Hopefully, most, if not all of the identified dependencies are in the "absolutely immutable" category. This generally means that services are referencing an explicit version of the dependency. So for example, a Java microservice with a POM file references a Maven dependency like camel-core version 2.15.1.redhat-621084. Because of the explicit version reference, this type of dependency can be considered immutable. This does not have significant implications on the design of your pipeline, because upgrades are applied to individual microservices, and require a commit to source code, which will naturally trigger a new build, test, and deployment cycle.
Build-time Variable Dependencies
Build-time variable dependencies are sneaky, especially in Docker environments. It is easy to fall into the mindset that a Docker image itself is immutable, therefore any dependencies packaged with the image are virtually "shrink-wrapped", and will not change. For example, a microservice's Dockerfile might start with a FROM instruction that references an image tag like latest, or a NodeJS service might reference a Git branch of a NPM module. Sure, after the microservice image is built for the first time, build-time version of those dependencies is preserved in the image. However, given that both Docker tags and Git branches can change over time, the next build of the microservice could yield surprising results. In other words, you could be accumulating technical debt between microservice builds because dependencies have changed. If you can, avoid build-time variable dependencies. If you cannot avoid them, reflect them in your pipeline by triggering dependent service builds whenever the dependency changes.
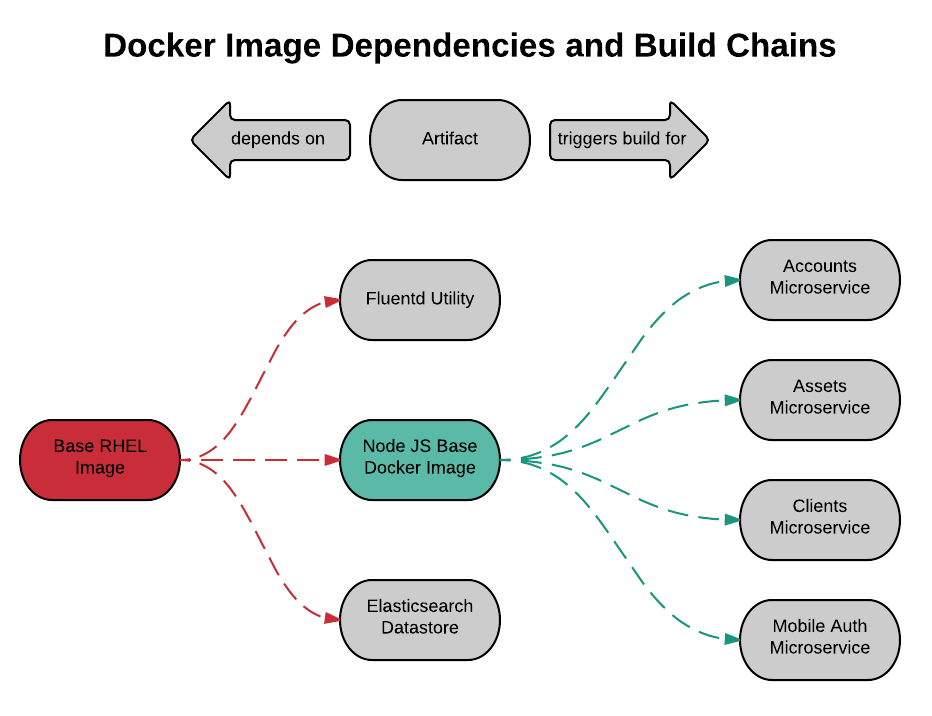
Here is another opportunity to derive some high-level user stories.
As a Systems Administrator, when I apply the
latesttag to a new base Docker image ID, all dependent images are rebuilt, tested, and promoted accordingly
Note that this example is only relevant if you are referencing an image tag. If you are referencing specific IDs for base Docker images, life is good, that's an immutable dependency. You will always get the same image regardless of build timing.
Run-time Variable Dependencies
Run-time variable dependencies are the nastiest. The best case is to simply avoid them altogether, if you can. A common example is a shared relational database where schema changes are introduced manually by database admins. Another example could be a poorly versioned API that is consumed by other services, for example a legacy service integration, when the legacy service involves a manual deployment process.
Continuous delivery pipelines rarely control the full scope of an architecture, especially in an integration context. Pay close attention to this category of dependency. Human interaction with your pipeline might be the only immediate option for coordination. Perhaps a user story is something like:
As a DBA, when I deploy a schema change to the test environment, I can notify the microservice continuous delivery pipeline to kick off a test suite and verify service compatibility against the new schema.
To clarify, you can certainly automate database schema changes and integrate deployments with your pipeline. This is just an example of a compromise when existing processes are not conducive to automation.
Maybe a future user story in this case is:
As a DBA, when I have prepared a schema migration script, I can commit the changes to a Git repository, triggering an automated schema migration against the test data environment.
Manual processes that affect dependencies in a microservice environment could be considered technical debt. It is a good idea to document and plan to automate.
Promotion
Finally, let's talk about environments. In my opinion, you have reached a state of cloud-Zen when the only static environment you have is 'production', and everything else is ephemeral and single-purpose. Non-production environments tend to sit around and do nothing most of the time, adding unnecessary cost, but that is a conversation for another time. In reality, most organizations are accustomed to promoting software changes through a sequence of static environments, e.g. dev > test > perf > stage > prod. This is another important conversation to have early. Define your environments, at least to the extent that their individual purposes are distinguishable. Here is an example:
- dev - the bleeding edge of all artifacts, experimental, unreliable
- test - stable releases and release candidates, observable by QA teams
- perf - matches prod resource profile, for simulating production load
- stage - observable by stakeholders, for demos and user story acceptance
- prod - end-user accessible
Promotion is how software becomes certified for deployment to the next environment in the sequence toward production. If you have a basic definition for your environments, define the certification criteria for each promotion.
Automated Tests
Ideally, promotion should occur as a result of successful automated test execution. A word to the wise: automating a continuous delivery pipeline is the easiest part of continuous delivery, developing the tests is the difficult part. As Andrew Lee Rubinger once put it, "Without testing, DevOps is merely the most efficient way to push bugs into production". For a really excellent presentation and demo about automated testing, have a look at Continuous Development with Automated Testing. But let's set aside the implementation details for now. In a planning phase, we can define promotion in fairly general terms. Here is another example user story:
As a product owner, if a software change passes automated tests in the performance environment, I can observe the change in the stage environment as a result of automated promotion.
Manual Tests
Sometimes manual testing is a requirement at some point during a release process. Whether this is because test automation is underdeveloped, or acceptance is only measurable by a human, or an organization simply mandates it, manual testing is a prevalent practice.
In my opinion, you are not kicked out of the continuous delivery club if manual testing is a part of your pipeline, although some may argue that the adjective "continuous" because meaningless at that point. So do you insert a deliberate pause into your pipeline? Yeah, kinda, but I tend to look at it as an automated test that fails (the first time) by design. Another user story:
As a Quality Assurance Tester, if a service change passes integration tests, and my team has not tagged the change as "certified", the change will fail validation before promotion to the perf environment.
You may eventually realize that manual testing can be automated after all. A purely automated continuous delivery pipeline can be viewed as a dangerous proposition to IT leadership. If your goal is to eliminate human intervention in your pipeline, go for it, it has been done! I highly recommend researching Feature Toggles. This pattern can help you separate the concept of feature releases from feature deployments. Also, research A/B testing and some other useful patterns for production releases. If you can believe it, "testing in production" is becoming an accepted practice (what a time to be alive).
Summary
This is my somewhat informal process for planning continuous delivery adoption at a user story level. Sprint planning at the beginning of a continuous delivery implementation can be a little daunting, so perhaps this can offer a framework for a planning session or two.
The short-and-sweet is this... Continuous delivery is actually an integration problem. Think about the inputs (source control events, dependency changes, human interactions), outputs (deployments, promotions), and validations (test suites, manual tests, user acceptance).